Rodrigo's personal site
Rodrigo/Gabriel/Twitch | EE & Programming
The inconsistent dataset in question is my store of Last.FM data for users who opt-in for leaderboards on a Discord Server. It consists of ~280k tracks, ~160 albums, and 80k artists.
We must always assume data from Last.FM is unclean, it does make reasonable attempts to collate mislabelled data into one (typically by redirecting artists names to one main page). However, with the plague that is the metadata from Spotify (the source of most track titles and album names) it causes quite the pain when trying to show a user an accurate leaderboard for who listens to what.
a far better solution would be to use a system similar to musicbrainz for credits on tracks and albums - such a rework would be quite the endeavour for last.fm but if they're hiring someone to do that I'll take the job ;).The structure for this dataset is created in such a way to deduplicate text stored and in a fast and efficient way collate who listens to what.
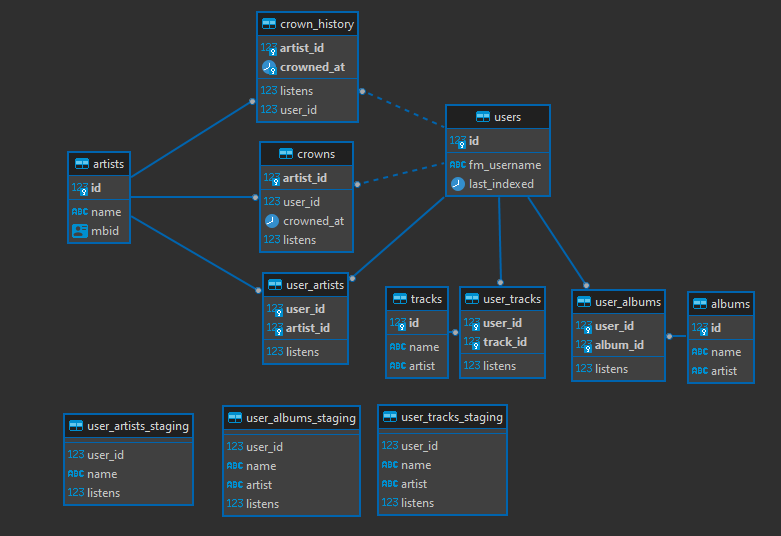
When a user has their data updated, it gets COPY'd into the user_x_staging tables which have no indexes for fast inserts. The data is then merged into the live tables, this process uses PSQL Functions in order to return an ID, creating an entity if it doesn't exist. Here's the query that merges up-to-date artist listens from staging to live, and the fetch_artist function.
INSERT INTO user_artists(user_id, artist_id, listens)
SELECT DISTINCT ON (LOWER(user_artists_staging.name)) user_artists_staging.user_id,
fetch_artist(user_artists_staging.name) AS artist_id, user_artists_staging.listens
FROM user_artists_staging
WHERE user_artists_staging.user_id = $1
GROUP BY user_artists_staging.user_id, name, listens
ON CONFLICT(user_id, artist_id) DO UPDATE SET listens = excluded.listens;
CREATE OR REPLACE FUNCTION fetch_artist(name VARCHAR)
RETURNS SETOF INT AS $$
BEGIN
RETURN QUERY SELECT id FROM artists WHERE LOWER(artists.name) = LOWER(fetch_artist.name) LIMIT 1;
IF NOT FOUND THEN
RETURN QUERY INSERT INTO artists (name)
VALUES (fetch_artist.name)
ON CONFLICT DO NOTHING
RETURNING id;
end if;
END; $$ LANGUAGE plpgsql;
You'll notice that in the function it selects artists by the LOWER of their name - quite often will artists that have mixed cases in their names have mislabelled data on Last.FM with the wrong case - by fetching regardless of case (and having only the first version be the case) we immediately remove lots of duplicate entries.
while writing this i noticed this wasn't the case in the dataset due to the data being quite old - however the links from user <-> artist should be accurate as duplicate names shouldn't be referenced thanks to the function using LOWER. ~0.02% duplicate albums, 0% albums (dataset was rebuilt) and ~0.68% for trackswell for some reason unknown to current me the function for fetching a track based on title and artist name,
I was writing this and then uni happened - I'll finish this once I find the motivation, this is still quite an interesting problem to be but electronics has taken over from the time I had to focus on programming